Rienforcement Learning to develop AI agents
Reinforcement learning (RL) is an area of machine learning concerned with how intelligent agents ought to take actions in an environment in order to maximize the notion of cumulative reward.Reinforcement learning is one of three basic machine learning paradigms, alongside supervised learning and unsupervised learning.
Reinforcement learning differs from supervised learning in not needing labelled input/output pairs be presented, and in not needing sub-optimal actions to be explicitly corrected. Instead the focus is on finding a balance between exploration (of uncharted territory) and exploitation (of current knowledge).
This project "Learning RL to develop AI agents" was offered by ACA(Association of Computer Activities IITK).
General Concepts :
Introduction to Machine Learning
Field of study that gives computers the ability to learn without being explicitly programmed. A computer program is said to learn from experience E with respect to some task T and some performance measure P,if its performance on T,as measured by P, improves with experience E.
Machine learning algorithms:
- Supervised learning
- Unsupervised learning
- Reinforcement learning.
Model Representation
Generaling speaking,The aim of the supervised learning algorithm is to use the given training Dataset and output a Hypothesis function.Where Hypothesis function takes the input instance and predicts the output based on its learnings from the training dataset.

Linear regression with one variable.
For linear regression in one variable,the hypothesis function will be of the form- h(x) = Θ0 + Θ1*x where, Θ0 and Θ1 are the parameters.
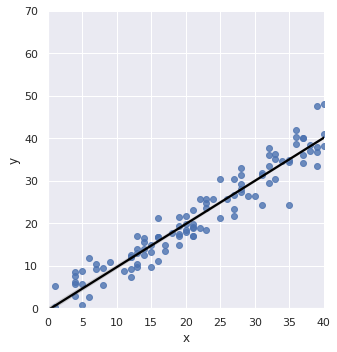
The line seen in the graph is the Hypothesis function. This line is the best fit that passes through most of the points. Now we know it’s not possible to tell the hypothesis function by merely looking at the graph! We need some systematic way to figure it out.
Cost Function helps us to figure out which hypothesis best fits our data. Or more formally,It helps us to measure the error of our hypothesis.It’s often called the squared error function. Mathematically, Cost function —
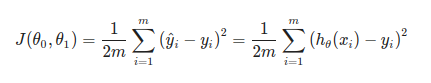
(h(x) — y)² : Squared vertical distances of the scattered points from the hypothesis.
∑(h(x) — y)²/2m: Average Squared vertical distances of the scattered points from the hypothesis, i.e Mean Squared error.
Now we have our hypothesis function and we also have a method of measuring how well it fits into the given data.All we need to do is find the value of parameters(Θ0 and Θ1) for which the cost function (i.e. error) is minimum. That’s where gradient descent comes into the picture
Gradient descent is an optimization algorithm for finding a local minimum of a differentiable function.Gradient descent is simply used to find the values of a function’s parameters that minimize a cost function as much as possible.Here
you can find more details about Gradient descent.
Mathematical form of Gradient Descent for Linear Regression-
repeat until Convergence:{
Theta(0) := Theta(0) - (α/m)* Σ(h(xi) - yi)
Theta(1) := Theta(1) - (α/m)* Σ(h(xi) - yi)
}
Note:- 1) Update Theta(0) and Theta(1) Simultaneously.
2) Σ is done for i=0 to m. where, m is Number of training examples in training dataset.
Here, α is the size of each step known as the Learning rate. The value of α should be selected with care to ensure that the gradient descent algorithm converges correctly in a reasonable time.
To be continued…
Come back soon for more:)
Go ahead and give some stuff here a read.